Рост производительности ЭВМ
Адресация данных в потоковой мультимикропроцессорной системе с магистральной структурой...
Узкие места потоковых вычислений
Организация вычислительного процесса в ЭВМ, управляемых потоком данных [1], в идеале основывается на потоковых схемах программ [2]. Главный принцип такой организации — отсутствие в программе явно заданной последовательности выполнения команд и активизация последних по готовности их данных — обеспечивает существенный рост производительности ЭВМ. Более широкий класс задач, чем потоковые, представляют являющиеся их прямым обобщением асинхронные схемы программ [2], хотя они и приводят к некоторым временным издержкам в вычислительных машинах с соответствующей организацией вычислений.
Основные трудности при построении потоковых или асинхронных ЭВМ — сложность внутрисистемного коммутатора и алгоритма управления им, а также отсутствие развитого алгоритмического языка, позволяющего строить детерминированные программы. Настоящая работа посвящена анализу «узких мест» в организации потоковых и асинхронных многопроцессорных систем и описанию смешанной потоково-асинхронной многошинной мультипроцессорной системы, далее называемой мультипроцессором с магистральной структурой, в которой эти узкие места практически отсутствуют. При анализе предполагалось, что число процессоров в мультипроцессоре достаточно для исполнения каждого оператора па своем процессоре. Такое идеализированное предположение сделано для того, чтобы исключить из рассмотрения вопросы рациональной диспетчеризации заданий, которые одинаково остро стоят для всех многопроцессорных систем с архитектурой MIMD [3].
В архитектуре потоковых ЭВМ в качестве основных используют два механизма: анализа готовности данных и передачи данных.
Готовность данных в асинхронных системах заменяется механизмом вычисления и анализа значения спусковой функции. При этом в общем случае анализ и подтверждение готовности осуществляются программно-аппаратными средствами с использованием специальных флагов готовности. Вычисление и анализ спусковой функции обеспечиваются выполнением соответствующей ей программы или одного оператора. Собственно вычислению и анализу должно предшествовать фактическое получение процессором, реализующим спусковую функцию, текущих значений всех ее аргументов.
Передача данных в известных системах осуществляется на основе одного из трех методов адресации: указания адресов операторов-получателей в операторе-формирователе данных; указания адресов операторов-формирователей в операторе-получателе данных; указания в операторах адресов памяти. Очевидно, использование адресации к памяти невозможно без применения флагов готовности, так как нельзя различить старые и новые значения данных (если только не используется язык единственного присваивания).
Рассмотрим недостатки описанных механизмов. При анализе готовности данных по флагу готовности и соответствующей ему передаче данных через память в системе образуется явно выраженное узкое место — память, работа с которой носит сугубо последовательный характер. В результате этого в рассматриваемом случае параллелизм потоковой ЭВМ становится существенно ниже параллелизма, заложенного в потоковой программе. При вычислении и анализе значений спусковых функций в асинхронных ЭВМ с передачей данных через память ситуация аналогичная. При явном задании адресов операторов-получателей резко уменьшается параллелизм, который может быть задан в исходной программе, так как число полей адреса в коде команды ограничено, причем, обычно, невелико (редко более двух), что вызвано ограниченностью длины всего командного слова. Поэтому распараллеливание по циклам, при котором достигается наибольший эффект от использования многопроцессорной системы MIMD, не может быть непосредственно реализовано в рассматриваемых системах.
Более естественна адресация операторов- формирователей данных, так как здесь небольшое число адресных полей в операторах в какой-то мере обусловлено небольшой и всегда ограниченной адресностью (т. е. число операндов) команд элементарных процессоров, образующих систему. Однако между числом обрабатываемых оператором данных и числом производителей этих данных есть тесная связь лишь при использовании алгоритмических языков или программ «с единственным присваиванием» Анализ готовности данных или значений спусковых функций при адресации потребителей данных не приводит к каким-либо издержкам, так как данные при этом находятся уже у потребителя. В то же время при адресации формирователей данных подобный анализ приводит к издержкам, во многом аналогичным возникающим при адресации через память.
Таким образом, базовые механизмы известных потоковых и асинхронных ЭВМ либо снижают степень параллелизма, присущего исполняемой программе, либо не позволяют строить программы с высокой степенью параллелизма.
В описываемом ниже мультипроцессоре с магистральной структурой совместно используются два типа адресации, которые, в совокупности, сочетают в себе достоинства описанных выше методов, по в основном свободны от их недостатков. Первым типом адресации является традиционное непосредственное указанием операторах адресов памяти, вторым — ассоциативная адресация. Применение адресации первого типа позволяет снять ограничения на характер и степень параллелизма, заложенного в прикладных программах, а применение второй, являющейся обобщением адресации операторов-производителей данных, дает возможность в более полном объеме реализовать этот параллелизм.
Простейший мультипроцессор с магистральной структурой, архитектура которого основана на адресации памяти и ассоциативной адресации, состоит из ряда элементарных процессоров и обобществленного устройства ввода-вывода. Выходы элементарных процессоров через элементы распределенного арбитра подключены к общим шинам, а посредством последних — к соответствующим модулям общей памяти, полные копии которых имеются в каждом элементарном процессоре. Элементарные процессоры имеют в своем составе помимо модулей процессора и памяти специальные блоки аппаратной поддержки потоково-асинхронной архитектуры и управления многошинным коммутатором.
При ассоциативной адресации данных каждому элементарному процессору доступна вся информация, которой обмениваются между собой операторы, независимо от наличия в нем собственных модулей общей памяти. Поэтому возможно двоякое толкование адресов данных, передаваемых по магистрали как собственно адресов общей памяти, используемых при обращении к ней, и как ассоциативных признаков передаваемых данных. В последнем случае исключается упомянутая выше необходимость многократного обращения к одним и тем же ячейкам памяти при неготовности данных. Кроме того, при ассоциативной адресации такого рода возможен одновременный обмен информацией между любым числом неконкурирующих источников и приемников, по крайней мере при достаточном числе шин. Здесь источники считаются не конкурирующими между собой, если они формируют одинаковые значения одних и тех же данных, и с приемниками, если они обращаются к одним и тем же данным.
Анализ готовности данных и значений спусковых функций в описываемом мультипроцессоре также базируется на двоякой интерпретации адресов памяти. Готовность данных здесь, как и вообще при адресации через память, подтверждается флагом готовности, который сопровождает передаваемые по шинам данные (для этого флага в системе предусмотрены специальные линии готовности, дополняющие стандартные общие шины, разрядность модулей общей памяти увеличена на единицу). Следовательно, готовность данных, как и их значения, может быть получена и проанализирована одновременно любым числом процессоров, каждый из которых, даже в худшем случае, выполнит такой анализ не более чем за одно обращение к общей памяти.
Анализ значений спусковых функций осуществляется путем одновременного выбора процессорами системы аргументов их соответствующих предикатов из всей массы передаваемых по магистрали данных. При неготовности данных также требуется не более одного обращения процессора к памяти на каждый аргумент предиката. Другим механизмом, используемым для эффективного вычисления и анализа значений спусковых функций, является аппаратная реализация базового набора спусковых функций, позволяющая преобразовать значения входных аргументов в значение соответствующего предиката быстрее, чем будет необходимо обработать следующие значения данных.
Использование адресации памяти и ассоциативной адресации позволяет эффективно реализовать еще одну функцию управления параллельными процессами, которая выходит за рамки асинхронных и потоковых схем программ. Такой функцией является синхронизация процессов с помощью семафоров [4]. Введение операций над семафорами в систему операторов мультипроцессора целесообразно в тех случаях, когда им должны решаться задачи с общими ресурсами, для которых прежде всего предназначены системы MIMD. Реализация семафорных операций основана на следующем.
Известно, что операция захвата процессором системы (двоичного) семафора представляет собой неразрывный цикл: получение текущего значения семафора, запись в качестве нового значения семафора нуля, анализ полученного процессором значения, возобновление цикла захвата или его завершение в зависимости от значения семафора; освобождение семафора представляет собой присвоение ему единичного значения. Поэтому, в рамках ассоциативной адресации, произвольное число процессоров может выполнить одновременно первую и вторую фазы операции захвата одного и того же семафора, несмотря на то, что непосредственный доступ к семафору выполнит лишь один из них. Аналогичное совмещение может быть осуществлено, когда операции захвата и освобождения семафора совпадают во времени. Единственным дополнительным действием, которое необходимо выполнить в случае, если процессоры получили единичное значение семафора, является передача этими процессорами в некотором фиксированном направлении информации о захвате семафора.
При подобном выполнении операций над семафорами нет никакой необходимости в циклическом опросе с помощью операций TEST & SET, применяемых в существующих мультипроцессорных системах (см., например, мультимикропроцессорную систему Minerva [4]). Как и при анализе готовности данных или значений спусковых функций, элементарные процессоры в мультипроцессоре с магистральной структурой выполняют не более одного фактического обращения к семафору при его нулевом значении. Непрерываемость семафорного цикла достигается введением в состав мультипроцессора единой для всей системы памяти семафоров (эта память не обязательно должна подключаться к специальной шине). Распространение в заданном направлении сигнала о захвате семафора обеспечивается распределенным арбитром шип, имеющимся в мультипроцессоре.
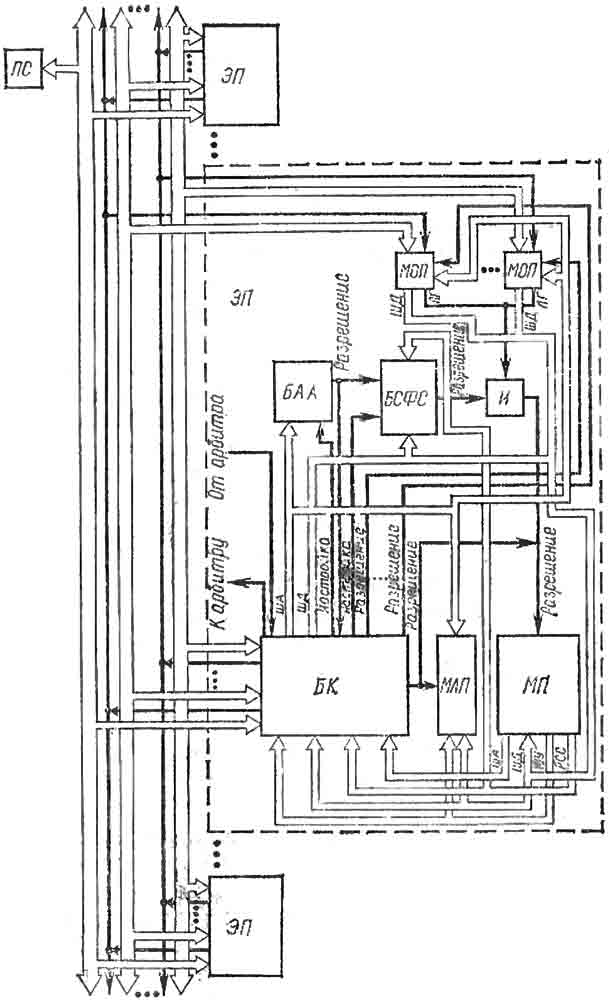
Мультипроцессор с магистральной структурой
С учетом сказанного выше можно достаточно легко описать работу узлов мультипроцессора, представленных па рисунке. Элементарные процессоры (ЭП) являются теми устройствами системы, которые выполняют отдельные операторы параллельной программы. Память семафоров (ПС) обеспечивает непрерываемость семафорного цикла. Блок коммутатора (БК) инициализируется, когда модуль процессора (МП) обращается к ячейкам памяти. При обращениях МП к локальной памяти БК просто выдаст сигнал разрешения обмена данными между модулем локальной памяти (МЛП) и МП. При обращениях МП к общей памяти БК анализирует тип исполняемой операции. Если выполняется операция записи информации в общую память БК автоматически дополняет информацию единичным значением бита готовности и передает ее по соответствующей шине во все ЭП. Если исполняется операция сброса бита готовности по некоторому адресу БК передает по соответствующей шине нулевое значение бита готовности при неопределенном значении остальных информационных разрядов.
В тех случаях, когда МП выполняет операции чтения, захвата семафора или анализа значений спусковых функций, БК передает блоку ассоциативной адресации (БАА) и (для последних двух операций) блоку анализа значений спусковых функций и семафоров (БСФС) сигналы настройки. По этим сигналам БАА получает из МП адрес ячейки общей памяти, из которой должна быть прочитана информация, а БСФС получает из МП код исполняемой операции и, для спусковых функций, значение константы, являющейся одним из двух аргументов предиката. После завершения настройки БК разрешает МП выполнить операцию чтения данных из соответствующего (собственного) модуля общей памяти (МОП) или из ПС. Чтение осуществляется в один или два этапа. Если бит готовности данного установлен и выполняется обычная операция чтения или бит готовности установлен и соответствующий предикат принимает истинное значение, или получено единичное значение семафора, то чтение выполняется в один этап. В противном случае на втором этапе БАА анализирует все адреса, пере даваемые по соответствующей шине, и при совпадении некоторого адреса с внутренним содержимым БАА последний запускает БСФС, который повторяет весь цикл анализа. Второй этап заканчивается, когда читаемое данное будет удовлетворять поставленным условиям.
Описанный мультипроцессор может быть без особой аппаратурной избыточности построен па основе серийных микропроцессорных БИС. Целесообразность использования микропроцессоров в качестве базы для построения потоковой системы с магистральной структурой обусловлена, во-первых, шинной организацией большинства микропроцессоров, позволяющей естественным образом сопрягать их с внешней магистралью, во-вторых, простотой введения системных функций в набор операции микропроцессора с помощью изменения его интерфейса, в третьих, малыми габаритными размерами и низкой стоимостью микропроцессорных БИС, что позволяет строить мощные мультипроцессоры со значительным числом процессоров. Следует отметить также, что альтернативами полному тиражированию общей памяти по элементарным процессорам могут служить частичное тиражирование, при котором фиксированная часть памяти является централизованной, а копии остальной имеются в каждом процессоре, и использование кэш-памяти [4].
Литература:
1. Trelcaven Р. С., Brownbridge D. R., Hopkins R. Р. Data-driven and demand-driven computer architecture. — Computing Surveys, 1982, v. 14, N 1 , p. 93—143.
2. Алгоритмы, математическое обеспечение и архитектура многопроцессорных вычислительных систем. /Под ред. А. П. Ершова. — М.: Наука, 1982. — 336 с.
3. Мультипроцессорные системы и параллельные вычисления /Под ред. Ф. Г. Энслоу. — М.: Мир, 1976. — 383 с.
4. Widdocs L. С The munerva multi-microprocessor. — In: Proceedings of the 3rd Annual Symposium on Computer Architecture, Clearwater, Fla., 1976, p. 34—37.
УДК 681.324
Р. И. Белицкий
Статья поступила 17 сентября 1984 г.
Комментариев нет.